
n8nでブラウザ操作を試したものの、スクリーンショットの日本語が全部「□□□」と文字化けしてしまったり、設定がうまくいかずエラーばかりで、心が折れそうになっていませんか?私も最初は同じ壁にぶつかり、何度も挫折しかけました。
でも大丈夫です。n8nでのブラウザ操作は、Docker環境に日本語フォントを追加するというひと工夫と、基本となるPuppeteerノードの使い方さえ押さえれば、驚くほどスムーズに動かせるようになります。
この記事では、私が実際に試して乗り越えた手順を元に、動的サイトからの情報取得やログイン自動化を実現するためのコツをまとめました。
読み終える頃には、きっと面倒なWeb作業をn8nに任せられるようになっていると思います。
- Docker環境での日本語文字化けの完璧な解決策
- Puppeteerノードを使った動的サイトのスクレイピング手順
- ログイン自動化や無限スクロールを攻略する実践テクニック
n8nでのブラウザ操作が必須になる動的サイトの仕組み
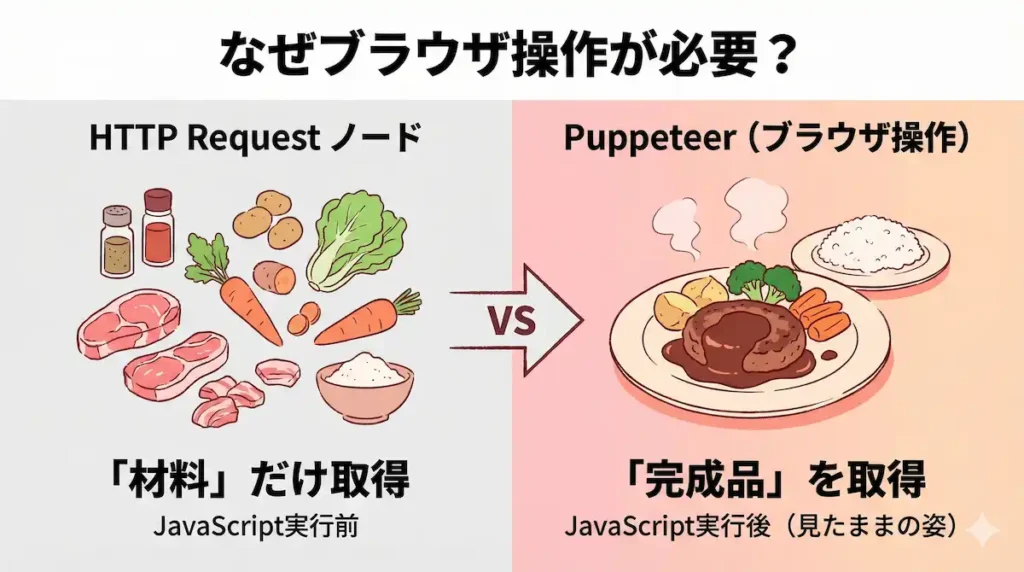
n8nでWebサイトから情報を集めようと思った時、多くの場合はHTTP Requestノードで十分だったりしますよね。
でも、いざ試してみると「サイトに表示されている情報なのに、なぜか取得できない…」なんて経験、ありませんか?
実はそれ、最近のWebサイトが持つ特別な仕組みが関係しているんです。
このセクションでは、どうしてブラウザを直接動かす操作が必要になるのか、その理由を一緒に見ていきましょう。
HTTP Requestノードでは歯が立たない理由
Webサイトには、サーバー側でページを完成させてから私たちに届けてくれるタイプと、ページの材料だけを先に届けて、私たちのパソコンやスマホの中で組み立てて表示するタイプがあります。
HTTP Requestノードが取得できるのは、この「材料」の部分だけなんです。
そのため、ブラウザの中でJavaScriptというプログラムが動いて初めて表示されるような情報、例えばボタンを押した後に表示されるデータや、リアルタイムで更新される価格などは、材料の状態では見つけられないんですね。
だからこそ、実際にブラウザを動かして、人が見るのと同じように組み立て後の完成したページを取得する必要が出てくる、というわけです。
データ取得だけじゃない!RPAとしてのブラウザ操作
n8nのブラウザ操作は、情報を集めてくるスクレイピングのためだけのものではありません。
むしろ、日々の繰り返し作業を自動化する「RPA(ロボティック・プロセス・オートメーション)」ツールとしても、すごく大きな力を発揮してくれます。
例えば、毎日決まった時間に特定のサイトにログインして、フォームに情報を入力して申請ボタンを押す、といった作業も自動化できます。
まるで、パソコンの中に自分専用の小さなアシスタントがいるみたいに、面倒な定型業務を黙々とこなしてくれるようになりますよ。
n8nのブラウザ操作で最初にぶつかる壁!日本語文字化けの完璧な解決策
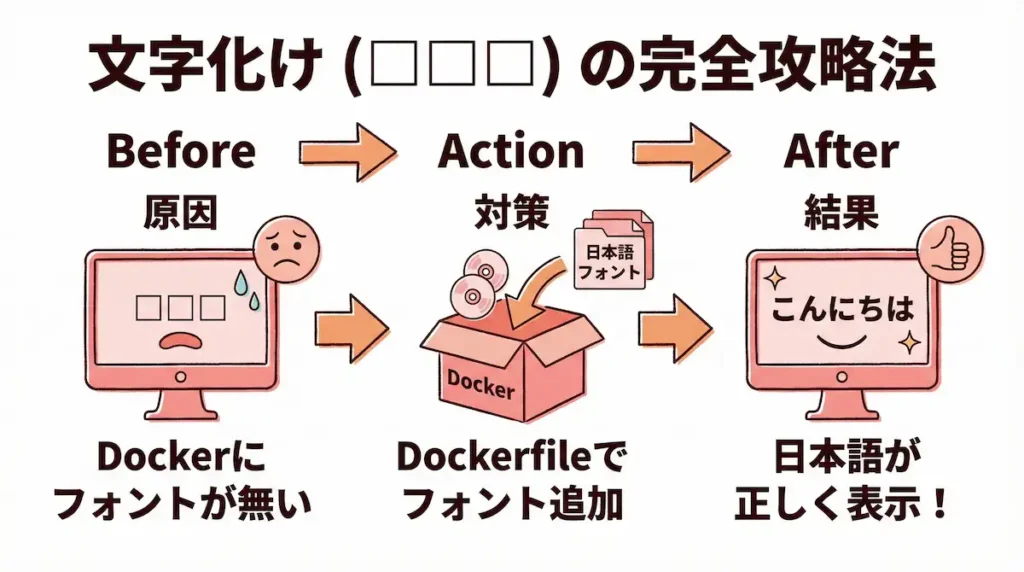
さあ、いよいよブラウザ操作に挑戦!と意気込んで、Webページのスクリーンショットを撮ってみたら、日本語の部分が全部「□□□」みたいに文字化けしてしまって…。私もここで一度、心が折れかけました。
でも、これはn8nでブラウザ操作を試したほとんどの人が通る道なので、安心してください。
原因はとてもシンプルで、もちろん解決策もちゃんとあります。
答えは、n8nを動かしているDockerという環境に、日本語のフォントを追加してあげること。
本当に、これだけなんです。
原因はDockerイメージの日本語フォント不足
なぜ文字化けが起きてしまうのかというと、n8nが動いているお部屋、つまりDockerイメージには、最初から日本語の文字セットが用意されていないことがほとんどだからです。
特に公式が配布しているイメージは、動きを軽くするために、機能に直接関係ないものはできるだけ削ぎ落としたシンプルな作りになっています。
そのため、日本語を表示しようとしても「どの文字を使えばいいか分からないよ」という状態になってしまい、代わりに四角い記号、通称「豆腐」で表示されてしまうんですね。
Dockerfileを編集して日本語対応イメージを作成する手順
この問題を解決するには、n8nのお部屋に「これが日本語のフォントだよ」と教えてあげる必要があります。
具体的には、n8nを起動するための設計図である「Dockerfile」というテキストファイルを少し編集して、日本語フォントをインストールする命令を書き加えます。
難しそうに聞こえるかもしれませんが、`font-noto-cjk`のような定番の日本語フォントパッケージを追加する数行のコードをコピーして貼り付けるだけで大丈夫です。
この一手間を加えるだけで、スクリーンショットやPDFでも、きれいな日本語が表示されるようになりますよ。
【基本編】n8nのブラウザ操作を実現するPuppeteerノードの始め方
日本語の問題がすっきり解決したら、いよいよブラウザ操作の本番ですね。
n8nでブラウザを動かすにはいくつか方法があるのですが、まずは一番メジャーで、できることも多い「Puppeteer(パペティア)」というコミュニティノードを使ってみるのがおすすめです。
ここでは、そのインストール方法から、最初の「動いた!」を体験できる簡単な使い方まで、一つひとつ順番に解説していきます。
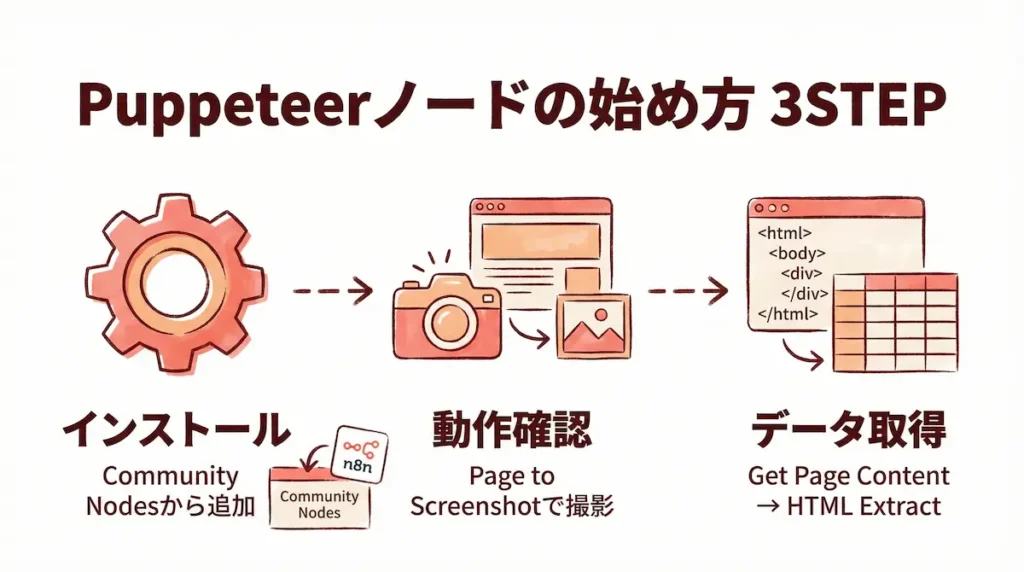
コミュニティノードのインストール方法
Puppeteerノードはn8nの標準機能ではないので、まずは追加機能としてインストールしてあげる必要があります。
n8nの管理画面を開いたら、右上にある歯車のアイコンから「Settings」を選び、次に「Community Nodes」という項目を探してみてください。
そこに表示される検索窓で「n8n-nodes-puppeteer」と入力すると、目的のノードが見つかるはずです。
「Install」ボタンを押して、少し待てば準備は完了。思ったより簡単だったのではないでしょうか。
最初のステップ:Webページのスクリーンショットを撮ってみる
まずは、一番シンプルで成功が分かりやすい、Webページのスクリーンショットを撮る機能を使ってみましょう。
ワークフローの編集画面にPuppeteerノードを追加したら、「Operation」という項目で「Page to Screenshot」を選びます。
あとは「URL」の欄に、お気に入りのWebサイトのアドレスを入力してワークフローを実行するだけ。
これで、そのページの画像データが生成されます。
この時に日本語がきちんと表示されていたら、前のセクションで行った文字化け対策は大成功ですね。
描画後のHTMLを取得してスクレイピングする
ブラウザ操作の主な目的がスクレイピングなら、「Get Page Content」という操作がとても便利です。
これは、JavaScriptなどが動いて、画面に表示されている通りの状態になったHTMLソースコードをごそっと取得してくれる機能なんです。
取得したHTMLは、次に「HTML Extract」という別のノードに渡してあげましょう。
そうすることで、特定の場所のテキストやリンクのアドレスだけを、きれいに抜き出すことができます。
この「Puppeteerで取得して、HTML Extractで抽出する」という流れが、n8nでの動的サイトスクレイピングの基本パターンになります。
【実践編】n8nのブラウザ操作でログインや動的サイトを攻略する3つのテクニック
基本的な使い方が分かってくると、もう少し難しいサイトにも挑戦したくなりますよね。
例えば、ログインしないと見られない会員専用ページだったり、画面を下にスクロールしないと全部の情報が出てこないサイトだったり。
ここでは、そんな少し手強いWebサイトを攻略するための、実践的なテクニックを3つご紹介します。
これができるようになれば、n8nで自動化できることの範囲がぐっと広がりますよ。
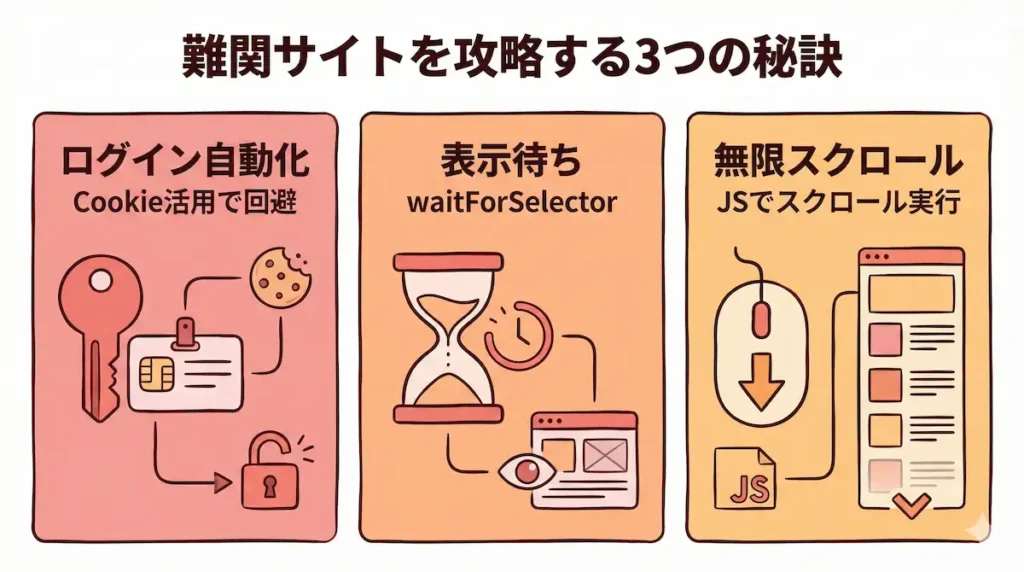
ID/パスワード入力とCookie活用によるログイン自動化
会員サイトへのログインも、Puppeteerの得意技の一つです。
「Type」という操作を使ってIDやパスワードの入力欄に文字を自動で入力し、「Click」操作でログインボタンを押す、というのが基本的な流れになります。
ただ、毎回この手順でログインしていると、サイトによっては不正アクセスを疑われてしまう可能性もゼロではありません。
そんな時は、一度ログインした後のセッション情報、いわゆる「Cookie」を保存しておいて、次回からはそのCookieを使ってログイン済みの状態から操作を始める、という少し賢い方法もおすすめです。
「waitForSelector」で動的コンテンツの表示を待つ
ボタンをクリックしてから、データが読み込まれて表示されるまでに、少し時間がかかるサイトってありますよね。
そんな時、何も考えずに次の処理へ進もうとすると、まだデータが表示されていないので「要素が見つかりません」というエラーになってしまいます。
ここで活躍してくれるのが「waitForSelector」という機能です。
これは「この目印となる要素が表示されるまで、ちゃんと待っていてね」とn8nにお願いする設定なんです。
単純に「5秒待つ」といった設定よりも、ページの状況に合わせてくれるので、ずっと確実でスマートな方法かなと思います。
無限スクロールも攻略!JavaScriptでページをスクロールさせる
SNSのタイムラインのように、ページを一番下までスクロールすると次の投稿が読み込まれる、いわゆる「無限スクロール」のページ。
これも自動化する上での悩みの種ですよね。
でも大丈夫。
Puppeteerには「Custom Script」という機能があって、ブラウザを直接操作するためのJavaScriptの命令を送ることができます。
例えば、「window.scrollBy」といったコードを実行させれば、ページを自動で下にスクロールさせられます。
これをループ処理と組み合わせれば、ページに表示される全ての情報を取得することも夢ではありません。
n8nのブラウザ操作が「落ちる」を防ぐ安定運用のコツ
せっかく時間をかけて作った自動化の仕組みも、いざ動かしてみたら途中でエラーになって止まってしまったり、n8nごと落ちてしまったり…。
そんな悲しいことにならないように、作ったワークフローを安定して動かし続けるためのコツを知っておくことは、すごく大切です。
ここでは、特に起こりがちな「メモリ不足」や「サイトからのアクセス拒否」といった問題への対策を、3つほどご紹介しますね。
メモリ不足エラーはDockerの設定で見直す
実は、Puppeteerを使ったブラウザ操作は、パソコンのメモリを想像以上にたくさん使います。
そのため、使っているマシンの性能によっては、n8nの動作が不安定になったり、フリーズしてしまったりすることがあるんです。
もしDockerを使ってn8nを動かしているのであれば、n8nを起動するときの設定で「n8nが使っていいメモリの上限」を少し増やしてあげると、この問題が解決することが多いです。
「–max-old-space-size」のようなオプションで調整できるみたいなので、一度調べてみるといいかもしれません。
タイムアウト設定を伸ばして読み込みが遅いサイトに対応
Puppeteerは、ページの読み込みなどの処理が30秒以内に完了しないと「時間切れです」と判断して、処理を中断してしまう初期設定になっています。
でも、サイトによっては読み込みに時間がかかったり、処理が複雑だったりして、30秒では足りないこともよくありますよね。
そんな時は、Puppeteerノードの設定で、このタイムアウトの時間を60秒や90秒など、長めに設定してあげると、n8nが焦らずにじっくりとページの表示を待ってくれるようになります。
これで、サイトの応答速度に左右されにくい、安定したワークフローになりますよ。
User-Agent偽装でボット判定を回避する
Webサイトの中には、プログラムによる自動アクセスを検知して、アクセスをブロックしてくる賢いサイトもあります。
その対策として有効なのが、「User-Agent」という、いわばブラウザの自己紹介情報を書き換える方法です。
Puppeteerノードの設定で、このUser-Agentを普段私たちが使っているような一般的なブラウザ(WindowsのChromeやMacのSafariなど)のものに偽装してあげることで、サイト側に「これは普通の人間からのアクセスですよ」と見せかけることができます。
これで、アクセスが成功する確率を高められるかもしれません。
【未来編】AIにお任せ!n8nの次世代ブラウザ操作「Browser Use」とは
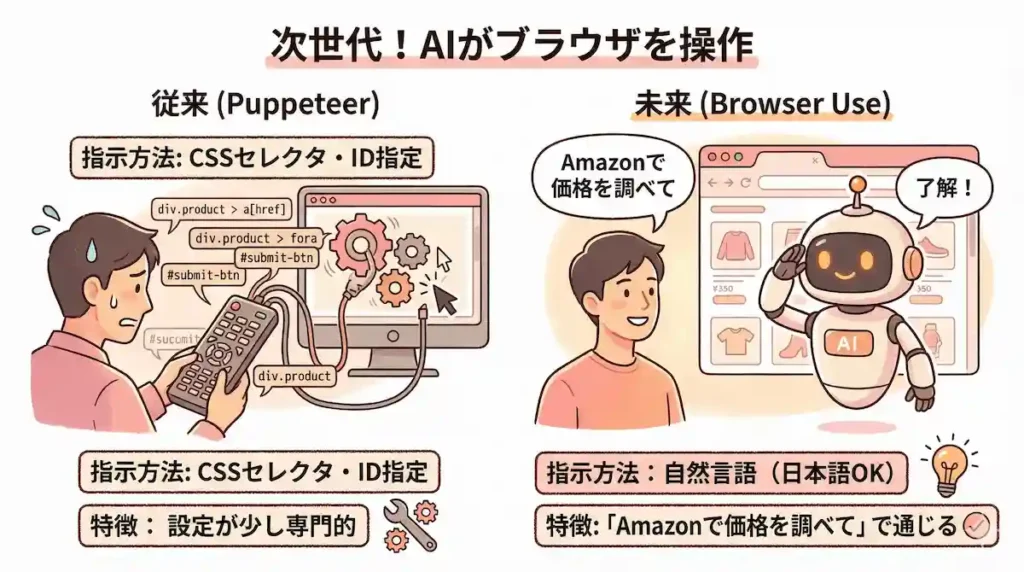
これまで見てきたPuppeteerは、本当に強力で便利なのですが、HTMLの構造を少し理解して「このボタンのIDは…」「この情報のCSSセレクタは…」と指定してあげる作業が、時には少し専門的で大変に感じることもありますよね。
そんな悩みを、未来の技術で解決してくれるかもしれないのが、AIを活用した新しいブラウザ操作ノード「Browser Use」です。
ここでは、その驚きの機能をご紹介しますね。
セレクタ指定不要!自然言語で指示できるAIエージェント
このノードが画期的なのは、私たち人間が普段話すような言葉で「Amazonで最新iPhoneの価格を調べてきて」とか「このページの問い合わせフォームから、この内容で送信して」とお願いするだけで、AIが自ら画面を見て判断し、クリックや文字入力といった操作を自動で行ってくれる点です。
まるで、パソコンの操作が得意なアシスタントさんにお願いしているみたいですよね。
裏側ではChatGPTのような賢い大規模言語モデル(LLM)が動いていて、私たちの代わりに面倒なブラウザ操作を全部引き受けてくれるんです。
APIコストと実行速度のトレードオフ
ただ、この夢のような機能を使うには、いくつか知っておきたいポイントもあります。
一つは、裏側で動いているAIのサービスを利用するための料金が、少しだけかかることです。
もう一つは、AIが人間のように「考えながら」動くので、Puppeteerでカチッと作り込んだ自動化に比べると、処理に少し時間がかかる場合があることです。
手軽さを取るか、コストとスピードを優先するか、自動化したい内容に合わせて使い分けるのが良さそうですね。
APIの利用料金などは、変更されることもあるので、提供元の公式サイトで最新の情報を確認してみてください。
まとめ:n8nのブラウザ操作をマスターし、Web自動化の可能性を広げる
今回は、n8nを使ったブラウザ操作の世界を、基本から応用、そして未来の技術まで一緒に見てきました。
HTTP Requestノードでは手が届かなかった動的なWebサイトの情報も、Puppeteerを使えばしっかりと取得できること、そして何より、多くの人が最初につまずいてしまう日本語の文字化けは、Docker環境にフォントを追加するという一手間で解決できる、ということが伝わっていたら嬉しいです。
私も最初は、あの「□□□」が並んだ画面を見て途方に暮れた一人なので、そのもどかしい気持ちがよく分かります。
でも、この壁を一度乗り越えてしまえば、Webからの情報収集から、日々の面倒な申請作業の自動化まで、n8nでできることの幅が本当に大きく広がります。
この記事が、Web自動化という新しい世界の扉を開く、小さなきっかけになったとしたら、これほど嬉しいことはありません。
ぜひ、ご自身の「これ、自動化できたら楽になるのにな」という想いを、形にしてみてくださいね。








